


Microsoft OneLake Explained: The Foundation for a Unified, AI-Ready Data Platform
In one of our previous blogs, we shared a recap of FabCon, where we briefly introduced one of Microsoft Fabric’s key building blocks: OneLake.
In today’s data-driven organizations, data exists everywhere; across cloud platforms, SaaS applications, legacy systems, and regional environments. While the volume of data continues to grow rapidly, meaningful insights often struggle to keep pace. This is rarely due to a lack of tooling, but rather the result of fragmentation. Data silos, duplicated datasets, and complex integration pipelines slow teams down and drive-up costs.
Microsoft Fabric addresses these challenges with OneLake, a unified data lake that serves as a single, shared storage layer for the entire organization. By centralising data in one logical place, OneLake fundamentally changes how data is stored, accessed, governed, and consumed.
In this blog, we’ll take a closer look at what OneLake is, why traditional data lake architectures fall short, the key capabilities of OneLake, and why it represents a strategic choice for modern data platforms.
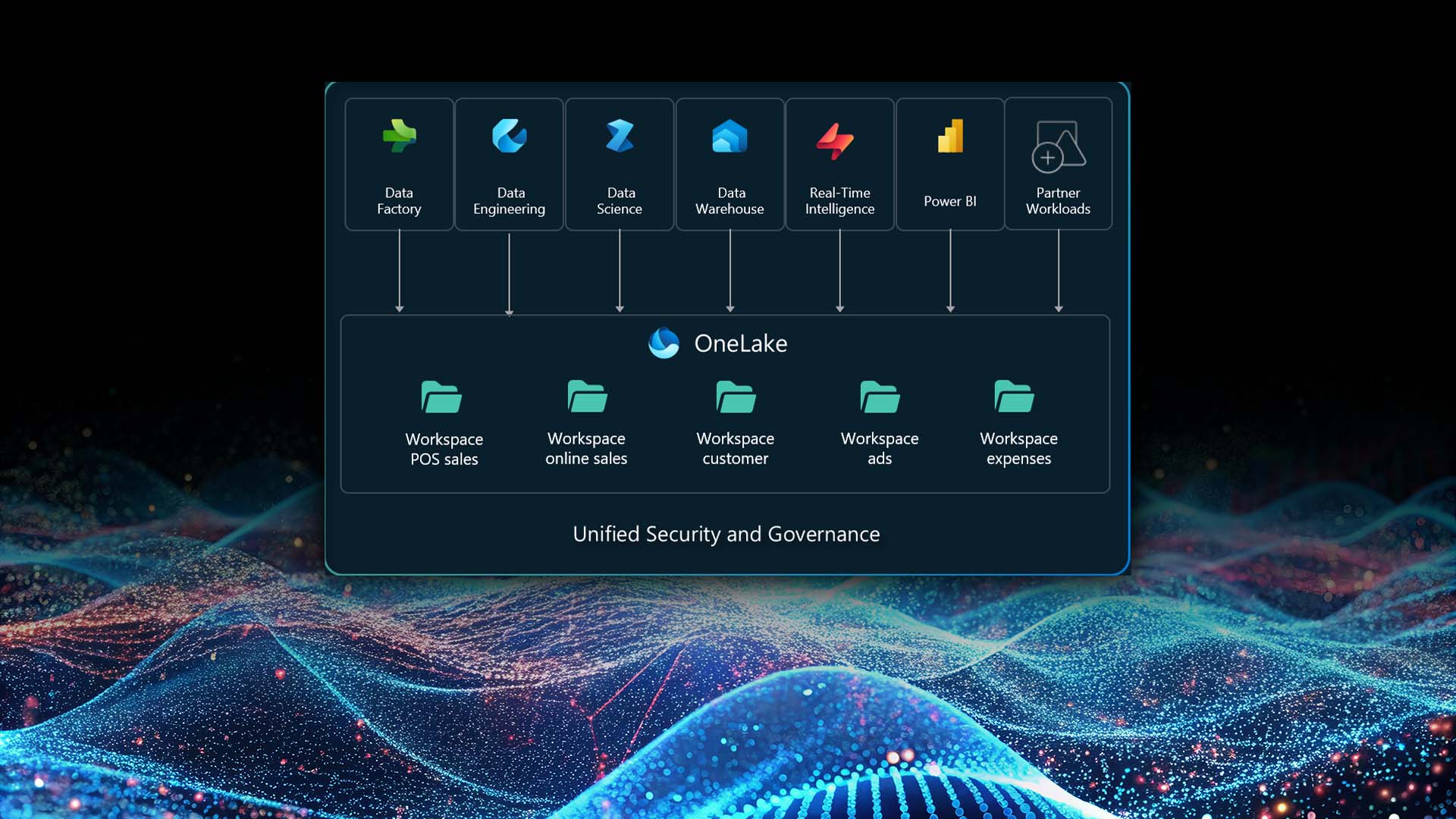
What is OneLake?
OneLake is an implementation of a Data Lake architecture. A data lake is a storage repository that holds large amounts of data in its native, raw format. Unlike traditional data warehousing architectures that only store structured data formats, data lake supports both structured and unstructured data. This gives additional possibilities to build data and AI solutions, which often require access to raw data, or event streaming and IoT use cases, where high-velocity data must be persisted at scale without upfront schema constraints.
Often described as the “OneDrive for data”, OneLake enables multiple teams and workloads to work with the same underlying data without unnecessary copying. Data engineers, analysts, and data scientists all operate on a shared foundation, while access and responsibilities remain governed through Fabric workspaces and security controls. Its tight integration with other Microsoft services enables it to make all data accessible inside OneLake. It also supports database mirroring for most SQL-based database types, enabling it to integrate data from external sources without any custom implementations.

Why traditional data lakes fall short
Traditional data lake architectures often lead to:
- Multiple disconnected storage systems owned by different teams
- The same datasets are copied across tools and environments
- Complex ETL pipelines to move and synchronise data
- Inconsistent governance, security, and data ownership
These challenges increase operational complexity, inflate storage costs, and delay insight delivery. OneLake addresses these issues by providing a unified, organization-wide data store with consistent governance.
OneLake’s core capabilities
Pros & cons of OneLake
OneLake’s value becomes clearest when looking at how it impacts collaboration, analytics, and AI, not just storage. Like any platform decision, it brings both strengths and trade-offs.
| Pros | Cons |
|---|---|
| Shared source of truth across teams | Requires clear workspace design, ownership, and governance models |
| Collaboration without data duplication | Needs a well-defined governance model to control who can use which data and for what purpose. |
| Machine learning directly on the data | Advanced analytics and ML still require skilled engineers, data scientists, and MLOps practices |
| Unified governance across analytics and AI | Initial governance setup takes time and planning |
| Future-ready foundation for AI | Maximum value is realised within the Fabric ecosystem |
Final thoughts
OneLake is not just another data lake implementation; it is the foundation of Microsoft Fabric’s vision for an integrated analytics and AI platform. By breaking down data silos and enabling teams to work from a shared source of truth, OneLake helps organizations move beyond fragmented reporting and isolated use cases.
Its real value emerges when data, analytics, and AI are treated as a single, connected capability rather than separate initiatives. Organizations that combine OneLake with strong governance, clear ownership, and domain-driven design can significantly improve both the speed and quality of decision-making.
As data volumes grow and AI becomes embedded in everyday business processes, platforms that reduce complexity while increasing trust and reuse will define the next generation of enterprise analytics. OneLake is a decisive step in that direction.